chatgpt算法解析 2023年Transformer架构下的量价选股策略 ChatGPT核心算法介绍
一、 核心算法介绍
是美国人工智能研究公司研发和训练的一款基于GPT算法的 大型对话式语言模型,通过RLHF( from ) 基于人类的反馈对模型进行强化学习的优化。与传统对话式语言模型相比, 不仅可以实现与用户真实流畅的交流,同时还具备许多其他功能,如文案 撰写、代码编写等,只需输入简单的关键词就能快速输出相关内容。
GPT( Pre- ,生成型预训练转换模型)是一种 基于海量数据预训练的深度学习文本生成模型,自2018年问世以来,经历了多轮迭 代和优化,目前使用的GPT-3.5模型中神经网络的参数超过1750亿个,是 有史以来参数最多的神经网络模型之一。同时,伴随着逐步出现在公众视 野,也在不断使用对抗性测试程序和的经验教训对GPT进行迭代调 整。2023年2月8日,微软宣布将的GPT-4模型集成到其搜索引擎Bing以及 Edge浏览器中,这意味着GPT-4将能够更加直接地服务于用户,提供更加便捷、智 能的搜索和交互体验;同时,也于2023年3月15日正式推出了大型多模态模 型GPT-4,该模型能够同时处理语音、图像、文本等多种输入,并生成高质量的自 然语言输出。
GPT模型的诞生,离不开其背后的核心算法:。模型 最早在机器翻译团队发表的论文 is All You Need中被提出,与RNN 和LSTM不同,它采用了完全不同的结构来处理输入序列。为了解决传统循环神经网 络在长序列上记忆能力不足、训练时间较长等问题,模型没有使用循环 的模型框架,而是通过引入注意力机制来有效地捕捉输入序列中各位置之间的相关性,建立输入和输出之间的全局依赖关系。因此,相比于传统循环神经网络, 模型不仅具有更好的解释性,并且可以进行更多的并行计算以缩短训练 时间。由于其出色的性能,模型和注意力机制成为了人工智能领域的研 究热点,并开始广泛应用于其他各个领域中。
(一)自注意力机制
自注意力机制的输入为词嵌入生成的词向量矩阵X或上一个编码层/解码层的输 出。对输入进行线性变换得到三个矩阵Q(查询)、K(键值)、V(值),矩阵X、 Q、K、V中每一列代表一个词向量(输入样本)。
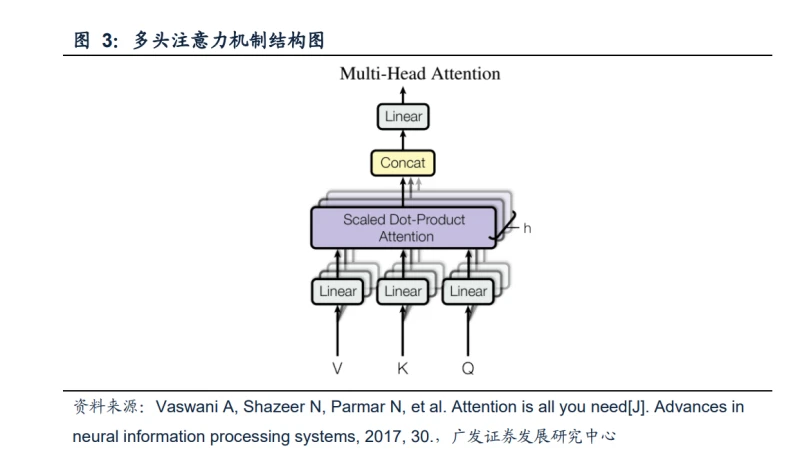
(二) 模型
模型的整体结构,主要由位置编码( )、 编码层()和解码层()组成。位置编码的作用是在词向量中加入 了单词在句子中的位置信息;编码器的作用是将序列中各位置之间关系的信息进行 编码并输出;解码器的作用是使用编码器输出的序列信息逐个词进行预测。
1. 位置编码
由于模型中没有使用循环的模型框架,直接利用全局信息,没有利 用单词的顺序信息,因此必须在词嵌入生成的词向量矩阵中加入单词的相对或绝对 位置信息。
2. 编码器
编码器由多个编码层堆叠组成,每个编码层又有两个子层,第一层是一个多头 自注意机制,第二层是一个使用ReLU激活函数的前馈全连接层。同时在每个子层后 都会使用残差连接,让网络更关注层与层之间差异的部分,然后还会进行层归一化,加快模型的收敛。 编码器的输入为经过词嵌入和位置编码后的序列矩阵chatgpt算法解析,输出为与输入矩阵大小 相同的包含序列中各位置之间关系的矩阵。
3. 解码器
解码器也由多个解码层堆叠组成,每个解码层中除了和编码层相同的两个子层 外,中间还有一层特殊的多头注意力机制,该子层使用解码层上一个多头注意力机 制子层输出线性变换得到的查询矩阵Q、编码器输出线性变换得到的键值矩阵K和值 矩阵V,执行多头注意力机制。与编码器类似,在每个子层后都会使用残差连接,然 后进行层归一化。 由于模型是逐个单词进行预测,因此解码器是串行进行的,每一步 会利用上一步的输出进行预测。在预测第一个单词时,解码器的输入为序列开始标 签,输出为第一个单词的预测;而在预测第二个单词时,解码器的输入为+第一个单词组成的序列,输出为第二个单词的预测;以此类推直至输出的 预测结果为序列结束标签。 而在训练时为了加速训练过程,标签值一般为整句输入,并行进行的,因此为 了保证训练和预测过程的统一,解码器中的第一个多头注意力机制会加入掩码操作, 确保对位置i的预测只能依赖于位置i以前的已知输出。
二、基于量价数据的股票涨跌预测模型
(一) 模型在股票涨跌预测中的应用
模型在NLP领域的巨大成功展示了它对序列数据的强大建模能力, 我们尝试将其思想引入到股票涨跌预测中。但模型最初是专为机器翻译 任务量身打造的,因此本报告对模型进行了以下三点修改使其适用于股 票预测模型:
1. 替换词嵌入层为线性层
在NLP领域,需要通过词嵌入将文本中的词转换为词向量作为输入,而在股票 数据中既有行业这样的分类数据,也有涨跌幅、换手率、财务指标等数值型数据。 如果输入只有分类数据则可以将时序看作是一个句子,继续使用词嵌入层;但在大 多数情况下,输入基本都会有数值型数据,不能通过词嵌入的方式进行转换。为了 能同时处理分类数据和数值型数据,我们将词嵌入层替换为常规的线性层,通过线 性变换代替词嵌入的过程。
2. 拓展数据输入到面板数据
在股票预测模型中,一般会输入多个特征的时序数据,即面板数据。虽然 模型最初是设计为接收一维序列(即一个句子)作为输入的,但通过将 词嵌入层替换为线性层的修改后,模型可以直接处理多维序列(即面板数据)。
3. 取消解码器的逐个预测机制和掩码操作
在NLP领域中,大部分任务可以转化为序列到序列()问题,即输入和 输出都是序列,如机器翻译、对话系统、语言识别等。为了利用已有输出,在NLP 问题中解码器会逐个样本进行输出,并在训练时使用掩码操作处理输入序列。而在 股票预测中,我们通常希望能准确预测未来一段时间的收益情况,因此模型输出一 般为一个值(回归问题)或涨跌概率(分类问题),因此我们对解码器进行简化, 取消了逐个预测机制和掩码操作。
(二)模型的数据处理和训练样本筛选
1. 缺失值处理
当股票某一时刻的特征值缺失时(上市不满20个月的情况除外),使用上一时 刻的特征值进行填充。
2. 极值、异常值处理
当股票的特征显著偏离同时刻股票特征数据时,设置边界阈值进行极值处理。 上边界为同时刻特征数据的均值加三倍标准差;下边界为同时刻特征数据的均值减 三倍标准差。当特征值超过上边界时用上边界替代;低于下边界时用下边界替代。 使得所有特征值位于相应的上边界和下边界之间。
3. 截面标准化
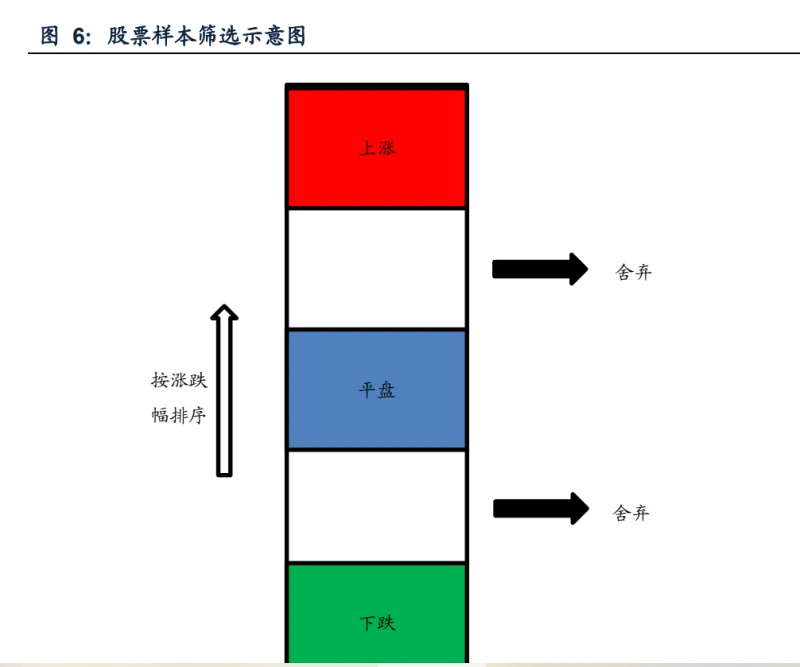
在处理完特征数据后,我们需要对股票的涨跌添加“标签”,作为模型的输出。 股票涨跌预测模型是希望预测出相对强势的股票,获得超额收益,因此我们对于每 一时刻的所有股票,根据未来一个月的涨跌幅来给不同的股票添加“上涨”、“平 盘”、“下跌”的“标签”。同时为了使不同标签样本之间的区别更明显且样本数 尽可能接近,我们还进行了样本筛选: 对每月对样本内的所有股票按下个月相对基准的超额涨跌幅进行排序,取涨幅 前20%的股票,标记为“上涨”;取涨幅居中20%的股票(涨幅位于40%分位数到 60%分位数之间),标记为“平盘”;取涨幅末20%的股票chatgpt算法解析,标记为“下跌”。 通过样本筛选,使得不同标签样本之间的区别更明显。如果不进行样本筛选,直接将所有股票按下个月的涨跌幅三等分,则位于不同标签分隔处的两只股票会被 划分至不同标签,但实际上两者之间的差异并没有那么大,这样的划分不利于机器 学习模型的训练。
(三)模型的参数选择和整体结构
序列向量维度(经过替代词嵌入层的线性层处理后的维度)、多头注意力机制头 数、编码器和解码器层数需要我们提前设定,通过网格搜索方法,参数组合确定为:
1. 序列向量维度d=64
2. 多头注意力机制头数h=8
3. 编码器和解码器层数N=6
最终模型结构如下: [20,2](输入层)→[20,64](线性层)→8×[20,8](编码层1)→8×[20,8](编 码层2)→8×[20,8](编码层3)→8×[20,8](编码层4)→8×[20,8](编码层5)→ 8×[20,8](编码层6)→8×[20,8](解码层1)→8×[20,8](解码层2)→8×[20,8] (解码层3)→8×[20,8](解码层4)→8×[20,8](解码层5)→8×[20,8](解码层6) →[3](输出层) 模型共有个参数需要进行训练。
三、策略实证分析
(一)中证 500 选股实证分析
本报告首先以中证500指数成份股作为股票池进行模型的训练和选股策略的回 测。从2000年至2019年获取样本进行训练,在2020年到2023年(样本外),用训 练好的预测模型进行策略回测。
1. 中证500选股-因子IC和分档收益率实证分析
因子IC是指个股截面因子值与个股下期收益率之间的相关系数,因子秩IC则是 指个股截面因子值排序与个股下期收益率排序之间的相关系数,两者都能够反映因 子提供超额收益的能力。在回测期内因子的IC表现和秩IC表现,IC平均值为0.034,标准差为0.081;秩IC平均值为0.027,标准差为0.092。
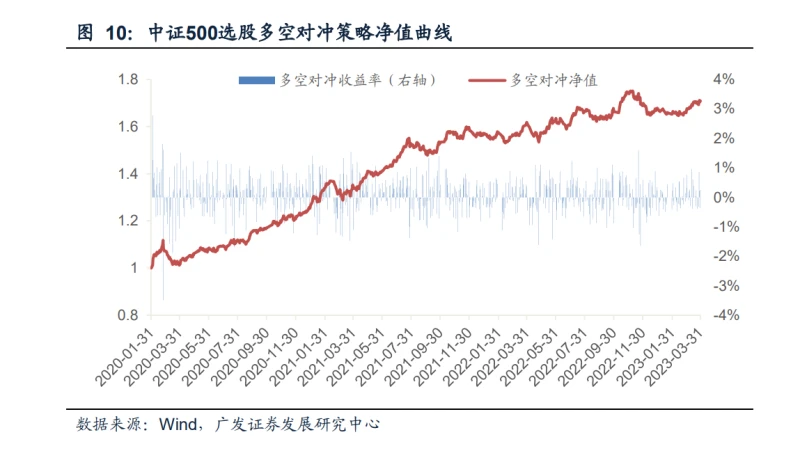
2. 中证500选股-多空对冲策略实证分析
假设可以卖空最低档(第五档)的股票,买入最高档(第一档)的股票,多空 对冲策略自2020年以来,策略的年化收益率为18.51%,最大回撤为-9.46%,日度 胜率为55.05%。
3. 中证500选股-指数对冲策略实证分析
以中证500指数为对冲标的,指数对冲策略自2020年以来,策略的年化收益率 为9.58%,最大回撤为-3.62%,日度胜率为54.40%。
指数对冲策略分年度的收益回撤情况如下表所示,策略每年都获得了正收益, 除了2023年的前3个月之外,指数对冲策略每年的收益率都超过了8%,且最大回撤 控制在-4%以内(注:2020年数据从2020年1月31日开始;2023年数据截止到2023 年3月31日)。
由于采用量价数据,策略的换手率较高,每次调仓的平均换手率为63.67%,年 化换手率为7.64倍。
前文中是按照0.3%的双边交易成本进行测算,如果将交易成本依次提高到0.4%, 0.5%和0.6%,指数对冲策略表现如下图和表所示。当交易成本提高时,策略表现有 所下滑,但总体表现稳定。
4. 中证500选股-模型训练参数讨论
在前文中证500选股实证分析中,由于需要处理一定规模的训练数据(约6万个 样本),为了提高计算效率并增强模型的泛化能力,避免过拟合,我们将 size 设置为128;同时,我们还在模型的收敛速度和稳定性上取一个折中,将学习率设置 为0.001。 在确定参数时,我们选择了一个相对稳定的区域,如下图所示。迭代次数 较小时,多头组合的收益率较低且存在较大波动;迭代次数过大时chatgpt算法解析,模型已经接近 收敛,且存在一定的过拟合,多头组合的收益率同样较低且不稳定;而在38 至52范围内,多头组合收益率整体上趋于平稳,并且有着较高的收益率。
(二)沪深 300 选股实证分析
其次,本报告将股票池转变为沪深300指数成份股,进行模型的训练和选股策略 的回测。从2000年至2019年获取样本进行训练,在2020年到2023年(样本外), 用训练好的预测模型进行策略回测。
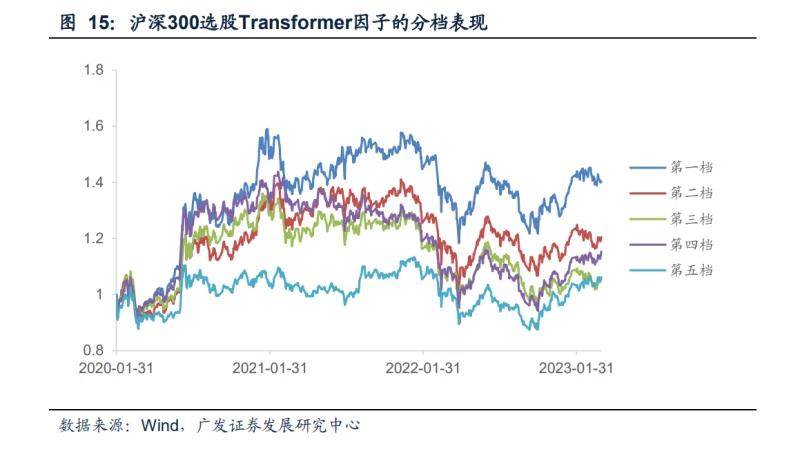
1. 沪深300选股-因子分档收益率实证分析
以1个月为调仓周期,在每一次调仓时,按照因子值的大小将股票分为5档,测试因子选股表现的单调性。
2. 沪深300选股-指数对冲策略实证分析
以沪深300指数为对冲标的,指数对冲策略自2020年以来,策略的年化收益率 为8.52%,最大回撤为-7.26%,日度胜率为52.85%。
(三)全市场选股实证分析
最后,本报告将股票池拓展至全市场A股,进行模型的训练和选股策略的回测。 从2000年至2019年获取样本进行训练,在2020年到2023年(样本外),用训练好 的预测模型进行策略回测。
1. 全市场选股-因子分档收益率实证分析
以1个月为调仓周期,在每一次调仓时,按照因子值的大小将股票分为5档,测 试因子选股表现的单调性。
2. 全市场选股-多空对冲策略实证分析
假设可以卖空最低档(第五档)的股票,买入最高档(第一档)的股票,多空 对冲策略自2020年以来,策略的年化收益率为15.58%,最大回撤为-12.09%,日度 胜率为56.61%。
多空对冲策略分年度的收益回撤情况如下表所示,策略每年都获得了正收益, 除了2023年的前三个月之外,多空对冲策略的收益率都超过了14%。(注:2020年 数据从2020年1月31日开始;2023年数据截止到2023年3月31日)
四、 模型与传统机器学习方法的对比
作为一种基于自注意力机制的神经网络模型,与传统机器学习方法进行比较时, 模型在股票涨跌预测任务中具有以下优点:
1. 处理长期记忆
在股票涨跌预测任务中,由于上涨或下跌趋势中伴随震荡区间,而在震荡区间 后涨跌往往并不取决于短期的震荡走势,而是更与长期记忆中的上涨或下跌趋势相 关。在循环神经网络(RNN)中,由于模型结构问题,难以有效地捕捉到时间序列 中的长期依赖关系;而在卷积神经网络(CNN)中,卷积核的大小通常是固定的, 因此只能考虑到局部信息,难以处理长期依赖。而模型通过引入自注意 力机制和位置编码突破了传统模型结构的限制,直接建模序列之间的全局依赖关系, 具备同时建模长期和短期时序特征的能力。
2. 变长输入序列
在股票涨跌预测任务中,历史数据的长度可能是不固定且存在缺失值的,传统 机器学习方法需要进行数据填充或截断处理不同的输入序列,在一定程度上影响了 模型的性能。而模型可以通过自注意力机制和位置编码直接处理变长的 输入序列,无需进行数据填充或截断,避免了信息浪费和预测偏差。
3. 并行计算效率
股票历史数据的长度通常很长,因此训练过程需要耗费大量时间和计算资源。 与传统机器学习方法相比,模型的多头注意力机制可以使得不同位置的 信息可以同时参与计算,从而实现了并行计算加速训练过程,进一步提高了训练的 效率,更适合处理大规模的时间序列数据。
4. 预训练模型提高泛化能力
模型的预训练模型(如BERT、GPT等)已经在自然语言处理等领 域取得了很好的效果,这些预训练模型可以用来初始化或微调模型,提 高模型的泛化能力。
五、总结与讨论
本报告将模型引入投资领域,运用其对于序列强大的全局建模能力 预测股票涨跌,通过对在中证500成分股、沪深300成份股以及全部A股中选股的实 证分析,证明了因子具有良好的组合管理能力。在回测期内,因子分档 结果具有较好的单调性,对冲获取的超额收益较为稳定。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
免责声明:本文系转载,版权归原作者所有;旨在传递信息,不代表本站的观点和立场和对其真实性负责。如需转载,请联系原作者。如果来源标注有误或侵犯了您的合法权益或者其他问题不想在本站发布,来信即删。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。