chatGPT模型参数 从语言模型到ChatGPT:大型语言模型的发展和应用(一)

前言
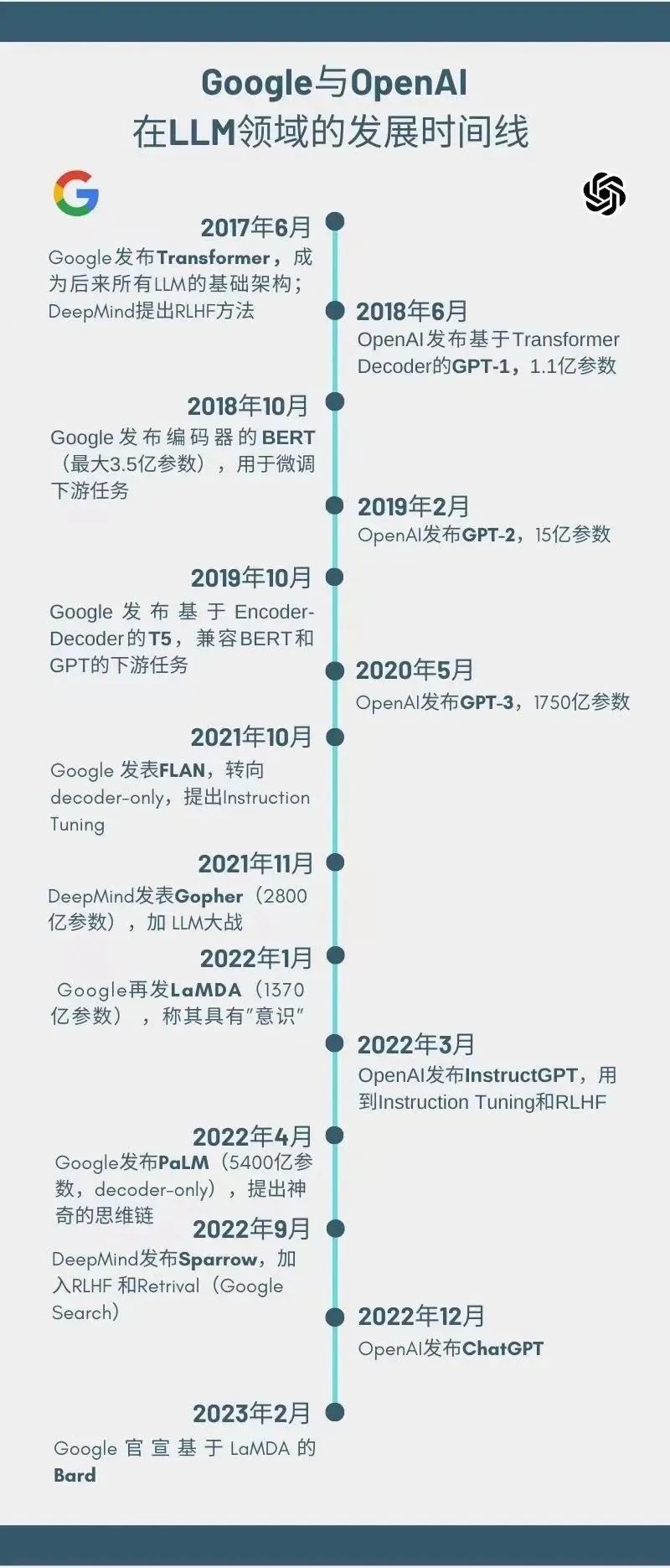
大型语言模型(LLM)是指能够处理大量自然语言数据的深度学习模型,它已经在自然语言处理、文本生成、机器翻译等多个领域中展现出了巨大的潜力。在过去几年中,LLM领域经历了飞速的发展,其中和作为两家领先的公司在这个领域中的表现备受关注。
是LLM领域的重要参与者,其BERT自编码模型和T5编码解码器在自然语言理解任务上取得了优异的表现。BERT模型通过预训练大规模文本数据,提取出词向量的同时,也能够学习到上下文信息。而T5模型则是在BERT的基础上,进一步将生成式任务融入其中,实现了一体化的自然语言处理能力。这些模型的出现,极大地推动了LLM领域的发展。
与之相反的是,则从2018年开始,坚持使用 only的GPT模型,践行着「暴力美学」——以大模型的路径,实现AGI。GPT模型通过预训练海量语料库数据,学习到了自然语言中的规律和模式,并在生成式任务中取得了出色的表现。坚信,在模型规模达到足够大的情况下,单纯的模型就可以实现AGI的目标。
除了和外,还有许多其他公司和研究机构也在LLM领域做出了贡献。例如,的模型、的 NLG模型等等。这些模型的不断涌现,为LLM领域的发展注入了新的动力。
如果只用解码器的生成式是通用LLM的王道,2019年10月,同时押注编码解码器的T5,整整错失20个月,直到2021年10月发布FLAN才开始重新转变为-only。这表明,在实际应用中,不同任务可能需要不同类型的模型,而在特定任务中,编码解码器的结构可能比-only模型更加适合。
本文将基于课件回顾大型语言模型的发展历程,探讨它们是如何从最初的基础模型发展到今天的高级模型的,并介绍的发展历程,看看如何实现弯道超车。
Zero-Shot (ZS) and Few-Shot (FS) In-
上下文学习(In- )
近年来,语言模型越来越倾向于使用更大的模型和更多的数据,如下图所示,模型参数数量和训练数据量呈指数倍增加的趋势。

模型名称
说明
备注
GPT
with 12 [参数量117M]
on : over 7000 (4.6GB text).
表明大规模语言建模可以成为自然语言推理等下游任务的有效预训练技术。
GPT2
Same as GPT, just (117M -> 1.5B)
on much more data: 4GB -> 40GB of text data ()
涌现出优异的Zero-shot能力。
GPT3
in size (1.5B -> 175B)
data (40GB -> over )
涌现出强大的上下文学习能力,但是在复杂、多步推理任务表现较差。
近年来,随着GPT模型参数量的增加,GPT2与GPT3模型已经表现出了极佳的上下文学习能力(In- )。这种能力允许模型通过处理上下文信息来更好地理解和处理自然语言数据。GPT模型通过Zero-Shot、One-Shot和Few-Shot学习方法在许多自然语言处理任务中取得了显著的成果。
其中,Zero-Shot学习是指模型在没有针对特定任务进行训练的情况下,可以通过给定的输入和输出规范来生成符合规范的输出结果。这种方法可以在没有充足样本的情况下chatGPT模型参数,快速生成需要的输出结果。One-Shot和Few-Shot学习则是在样本量较少的情况下,模型可以通过学习一小部分示例来完成相应任务,这使得模型能够更好地应对小样本学习和零样本学习的问题。
上下文学习介绍
大模型有一个很重要的涌现能力( )就是In- (ICL),也是一种新的范式chatGPT模型参数,指在不进行参数更新的情况下,只在输入中加入几个示例就能让模型进行学习。下面给出ICL的公式定义:
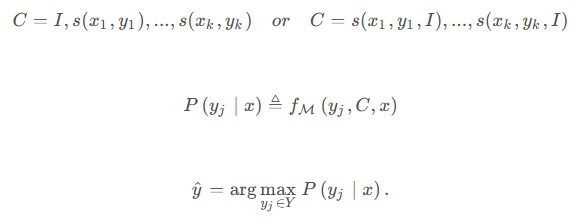
其中,符号含义如下,从这些符号中也能看出影响ICL的因素:
I:具体任务的描述信息
x:输入文本
y:标签
M:语言模型
C:阐述示例
f:打分函数
下面将开始介绍如何提升模型的ICL能力。
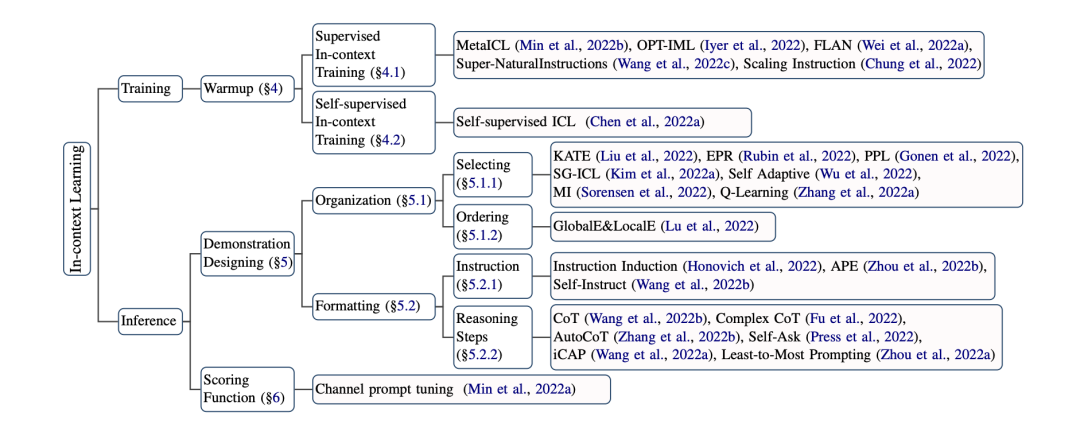
训练优化ICL能力
有监督训练:
在ICL格式的数据集上,进行有监督的训练。
就直接把很多任务整合成了ICL的形式精调模型,在52个数据集上取得了比肩直接精调的效果。另外还有部分研究专注于 ,构建更好的任务描述让模型去理解chatGPT模型参数,而不是只给几个例子(),比如-PT、FLAN。
自监督训练:
将自然语言理解的任务转为ICL的数据格式。

图1代表不同自然语言理解任务转为ICL的输入输出形式。
图2表示训练样本示例,包含几个训练样本,前面的样本作为后面样本的任务阐述。
推理优化ICL能力
设计
样本选取:文本表示、互信息选择相近的;选取;语言模型生成……
样本排序:距离度量;信息熵……
任务指示:APE语言模型自动生成
推理步骤:COT、多步骤ICL、Self-Ask
打分函数
:直接取条件概率P(y|x),缺点在于y必须紧跟在输入的后面;
:再用语言模型过一遍句子,这种方法可以解决上述固定模式的问题,但计算量增加了;
:评估P(x|y)的条件概率(用贝叶斯推一下),这种方法在不平衡数据下表现较好。
影响ICL表现的因素
预训练语料的多样性比数量更重要,增加多种来源的数据可能会提升ICL表现;
用下游任务的数据预训练不一定能提升ICL表现,并且PPL更低的模型也不一定表现更好;
当LM到达一定规模的预训练步数、尺寸后,会涌现出ICL能力,且ICL效果跟参数量正相关。
免责声明:本文系转载,版权归原作者所有;旨在传递信息,不代表本站的观点和立场和对其真实性负责。如需转载,请联系原作者。如果来源标注有误或侵犯了您的合法权益或者其他问题不想在本站发布,来信即删。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。