编程神器Copilot逐字抄袭他人代码?

编译|核子可乐、燕珊
“ 向开源软件注入了自私的基因:我想要什么,你就得给我什么。”
自面世后就饱受争议的 编程神器最近又遭遇舆论风暴。
日前,德州农工大学的一位计算机科学教授 Tim 在推特上发文称, 在没有标注来源也没有 LGPL 许可的情况下,输出了大量应该受版权保护的代码。
Tim 还发了自己和 在稀疏矩阵转置、稀疏矩阵加法的代码对比,并表示两者几乎一模一样,高度雷同。Tim 的推文引发热议, 技术总监认为这算是 非法洗代码行为。
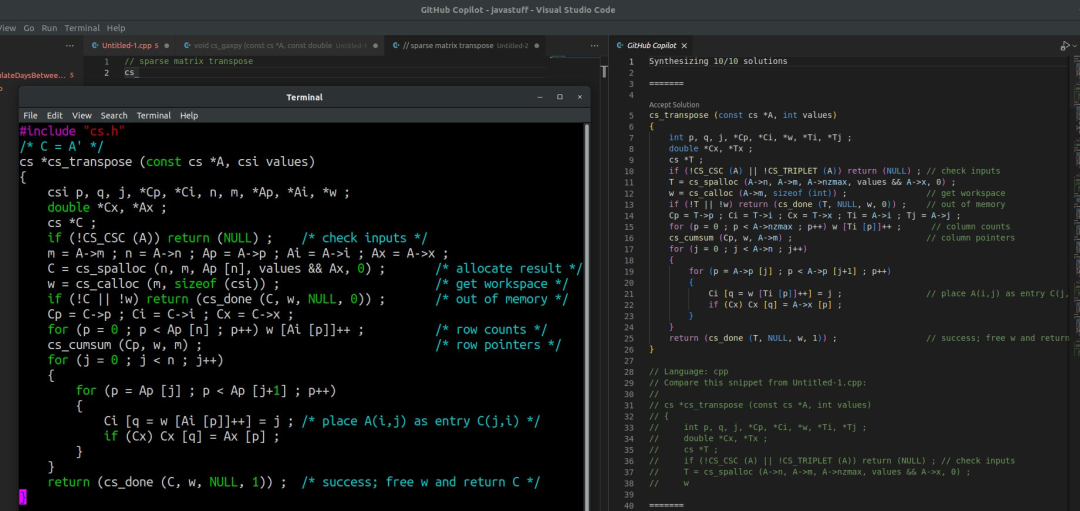
左边是该名教授的代码,右边是 的。
对此, 的发明者 Alex 回应道,Tim 写的代码和 产生的代码不同,“相似,但不同”。他还提到,如果有人能提供一种方法可以自动识别代码是由某一方衍生出来的,那就可以申请专利了。
Alex 表示,到目前为止 已被指控了诸多问题,包括剽窃代码、引入漏洞、代码不完美、太分散注意力、甚至让人变笨等等。他强调道,“我认为程序员永远不会被取代。 使人们的工作效率更高。”
起诉
是一款 AI 结对编程工具,它的主要定位是提供代码补全与建议功能。它是 Code 的一个插件,可根据当前文件的内容和当前光标位置为你自动生成代码。而版权问题是 从一推出就面临的挑战,人们质疑它在 上发布的公开代码上进行训练的合法性。
除了 Alex 的“怒怼”,这两天在 上引起热议的还有另一篇内容《也许你并不在乎 在未经许可之下使用你的开源代码,但如果 要抹除整个开源社区,你又将作何感想?》,这篇文章来源于一位名叫 的律师,同时他也是一名程序员。
作为程序员, 从 1998 年起就在专业参与开源软件贡献,期间还在 Red Hat 工作过两年。最近,他又成了 的贡献者。他写过文章宣传 Lisp,也出过介绍编程语言开发的书,还发布过不少开源软件,包括专门用来出版线上书籍的 ,以及他自己在工作中经常使用的 AI 软件。
今年 6 月,在 正式推出的时候, 写了一篇关于 违法问题的文章。而最近, 决定采取下一步行动,重新激活了自己的加州律师协会会员资格,并和几位律师发起了新的项目——针对 违反对开源作者及最终用户的法律义务一事开展调查,并考虑进行诉讼。
的问题在哪?
首先要说明的是, 跟传统自动补全功能有何区别?简单来讲, 由 进行支持,而 则是由 构建并授权给微软的 AI 系统(微软常被称为「 的非官方所有者」)。 能根据用户输入的文本 提供建议,而且与只能提示细节建议的传统工具不同, 可以提供更大的代码块,包括函数的完整主体。
但作为底层 AI 系统, 是怎么被训练出来的?据 的介绍, 接受了“数以千万计的公共 repo”的训练,其中当然包括 上的代码。微软的说辞则较为含糊,只提到“数十亿行公共代码”。不过 研究员 最近已经在播客中证实, 确实是“由 上的公共 repo 训练而成”。
认为,“ 在系统训练与系统使用方面都存在法律问题。”
系统训练
绝大多数开源软件包是在授权许可之下发布的,在授予用户一定权利的同时也要求其承担一定义务(例如保留源代码的精确属性)。而这种授权的合法实现方式,就是由软件作者在代码中声明版权。
因此,要想使用开源软件,大家就必须做出选择:
要么遵守许可证所规定的义务;
要么使用那些属于许可证例外的代码(即版权法所规定的「合理使用」情形)。
如果微软和 决定基于各 repo 的开源许可来使用这些训练素材,那就得发布大量属性(),这已经算是各类开源许可的底线要求。但截至目前,大家都还没有看到任何属性声明。
微软和 必须找到“合理使用”的理由。 前 CEO Nat 就曾在 的技术预览会上提到,“在公开数据上训练(机器学习)系统属于合理使用的范畴。”
然而,软件自由保护组织(SFC)明显不同意他的观点,并要求微软方面提供能支持其立场的证据。保护组织负责人 Kuhn 指出:
我们曾在 2021 年 6 月私下询问过 和其他几位微软 / 代表,要求他们为 的公开法律立场提供可靠的参考依据……但他们什么都拿不出来。
事实上,目前全美还没有哪个判例能够直接解决 AI 训练中的“合理使用”问题。另外,所有涉及“合理使用”的案例均权衡了大量相关因素。即使法院最终判定某些类型的 AI 训练属于“合理使用”,也不代表其他类型的训练就能“无脑照办”。就目前来看,还不知道 和 到底合不合法,微软和 其实也说不准。
系统使用
虽然没法确定“合理使用”最终要怎么在 AI 训练中落地,但可以想象,其结果并不会影响到 用户。为什么呢?因为用户只是在使用 提供的代码,而这部分代码的版权和许可状态同样模糊不清。
微软倒是有自己的说法。2021 年,Nat 曾声称 的输出结果归属于操作者,其性质与使用编译器一样。但 已经暗暗给用户挖好了坑。
微软将 输出描述为一系列代码“建议”,并强调不会对这些建议“主张任何权利”。但与此同时,微软也不会对由此生成的代码的正确性、安全性或延伸出的知识产权问题做任何保证。所以只要接纳了 的建议,那这些问题就都要由用户自己承担:
您需要对自己代码的安全性和质量负责。我们建议您在使用由 生成的代码时,采取与使用其他一切非本人所编写代码相同的防范措施,包括严格测试、IP(知识产权)扫描和安全漏洞跟踪。
这样一来,可能会产生什么纠葛?用户控诉,就像上文中 Tim 控诉的这起抄代码事件。
理论上, 使用他的代码,当然会产生相应的许可遵守义务。但从 的设计来看,用户完全接触不到代码的来源、作者和许可证。
从这个角度看, 的代码检索方法就像一颗烟雾弹,下面掩盖的是另一种真相: 本身,只是连通海量开源代码的一套替代接口。只要用上它,用户可能就需要承担起代码原作者提出的许可义务。
意识到这一点,Nat 所谓 “就像是编译器”的说法就会变得不靠谱。毕竟编译器只会改变代码形式,但绝不会注入新的知识产权属性。
对于开源社区意味着什么?
认为,通过将 当作海量开源代码的替代接口,微软不仅借此切断了开源作者与用户之间的法律关系,甚至建立起新的“围墙花园”——阻止程序员接触传统开源社区,从而消除了他们为之贡献的可能性。随着时间推移,这势必会让开源社区变得愈发贫乏。
用户的注意力和参与方向将逐渐朝着 转移,最终彻底告别开源项目本身——告别源代码 repo、告别问题跟踪器、告别邮件列表、告别讨论板。这样的变化必将给开源带来痛苦、甚至永远无法挽回的损失。
“包括我自己在内的开源开发者之所以提出抗议,所图的绝不是钱。我们只是不想让自己的努力贡献被白白浪费掉。开源软件的核心在于人,在于由人组成的用户、测试者和贡献者社区。正是因为有了这样的社区,我们才能以超越自身的方式改进软件,让工作充满乐趣。” 进一步说道, 向开源软件注入了自私的基因:我想要什么,你就得给我什么。
他最后强调道:“我们反对的绝不是 AI 辅助编程工具,而是微软在 当中的种种具体行径。其实微软完全可以把 做得更开发者友好一些——比如邀请大家自愿参加,或者由编程人员有偿对训练语料库做出贡献。但截至目前,口口声声自称热爱开源的微软根本没做过这方面的尝试。另外,如果大家觉得 效果挺好,那主要也是因为底层开源训练数据的质量过硬。 其实是在从开源项目那边吞噬能量,而一旦开源活力枯竭, 也将失去发展的依凭。”
参考链接:
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。