AI生成的代码你敢用吗?有人给最近走红的
近日, 推出了一款利用人工智能生成模型来合成代码的工具——,但发布之后却饱受争议,包括 和。除此之外,生成的代码能不能用、敢不敢用也是一大问题。在这篇文章中, 测试受邀用户 在试用该代码合成工具后发现了一些值得关注的安全问题,并以此为基础写了一份简单的风险评估报告。
真好,就算我因为 ICE 已经叨扰了他们好几百次,他们还是给予了我进入 测试阶段的权限。这次,我不关心 的效率,只想测试它的安全性。我想知道,让 AI 帮人写代码风险有多高。
每一行提交的代码都需要人来负责,AI 不应被用于「洗刷责任」。 是一种工具,工具要可靠才能用。木工不必担心自己的锤子突然变坏,进而在建筑物内造成结构性缺陷。同样地,程序开发者也应对工具保有信心,而不必担心「搬起石头砸自己的脚」。
在 上,我的一位关注者开玩笑说:「我已经迫不及待想用 写代码了,我想让它写一个用于验证 JSON 网页 的函数,然后看都不看就提交上去。」
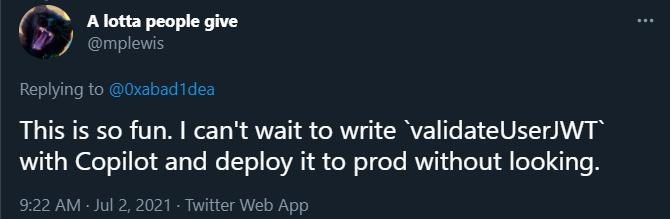
我按照这一思路使用了 ,得到的结果很是搞笑:
(jwt: ): { true;}
除了删除硬盘驱动器之外,这可能是最糟糕的实现了。这种错误是如此明显、粗陋,任何专业的程序开发者对此都不会有异议。我更感兴趣的是 是否会生成乍一看很合理的代码,以至于其中的错误会被程序员忽视或被经验不足的程序员认为是正确的。(剧透一下:确实会出现这种情况。)
我有意使用 生成实际应该人工编写的代码,因为用户肯定会在生产过程中这样做。
不确定性
是一种生成模型,这意味着其目的是生成在统计学意义上近似其输入(即训练数据)的输出结果。其目标并不是精准重现其输入,因为单纯的复现并不需要机器学习系统。这类模型有一个通常被称为「温度()」的参数,这是一个滑动比例,可在保守风格(模仿最常见的输入)和原创风格之间调整。原创性设置越高,输出的结构化程度就越低,就越有可能得到垃圾结果。 的温度由 控制,据说他们会根据当前试验阶段而对其进行调节。
以同样的方式调用一个生成模型两次,通常并不会得到两个同样的结果。它每次都会重新运行一次自己的统计模型。这有其优势——如果你不喜欢该模型的前一个建议,你可以再次提问。这也能减少 为不同用户生成相同代码的数量。但是,这与可靠性最基本的原则之一(即确定性)并不一致。它有可能在某一天完全按照你的样本文件执行,而在第二天又完全做错。
举个例子,使用完全一样的输入(一个仅包含注释、关键词 “” 和一个空格的文件),我得到了以下两个不同的月相计算器实现:
月相计算器 A
// the of the () { var = Math.((new Date().() - new Date().(0,0,0,0)) / ) % 28; if ( == 0) { "New Moon"; } else if ( == 1) { " "; } else if ( == 2) { " "; } else if ( == 3) { " "; } else if ( == 4) { "Full Moon"; } else if ( == 5) { " "; } else if ( == 6) { "Last "; } else if ( == 7) { " "; }}
月相计算器 B
// the of the () { var = Math.((new Date().() - new Date(new Date().(), 0, 0).()) / (1000 * 60 * 60 * 24)) + 1; if ( > 29) { = 29; } ;}
粗略一看,它们完成的任务好像一样,但其中一个实现会将一个月份分为 8 个月相,每个月相包含若干天,然后返回日期对应的月相文本标签;另一个则像是将每个月份的每一天视为一个不同的月相且没有文本标签。但实际上它们都做错了。计算器 A 说 2021 年 7 月 2 日是新月,而人工编写的天文学网站则表示 2021 年 7 月 2 日是残月。计算器 B 则在 值高得离谱(>29)时,将月相设为29。这两个实现乍一看都是可行的,而如果你比较一些结果,你会发现很难说其中哪一个是正确的。
实际上,我在生成一个复活节日期计算器时多次得到了完全一样的输出结果,而且这个计算器是正确的(至少在我验证过的一些年份上是正确的)。我猜想这意味着复活节计算器实现之间的偏差要比月相计算器之间的偏差小得多。
复活节计算器
// the date for a (y) { var a = y % 19; var b = Math.(y / 100); var c = y % 100; var d = Math.(b / 4); var e = b % 4; var f = Math.((b + 8) / 25); var g = Math.((b - f + 1) / 3); var h = (19 * a + b - d - g + 15) % 30; var i = Math.(c / 4); var k = c % 4; var l = (32 + 2 * e + 2 * i - h - k) % 7; var m = Math.((a + 11 * h + 22 * l) / 451); var n0 = (h + l + 7 * m + 114) var n = Math.(n0 / 31) - 1; var p = n0 % 31 + 1; new Date(y, n, p);}
可解读性
上面的复活节计算器是正确的,但我也只是通过实验知道的;它实在太难以解读了。(更新:有人在评论区指出有一个书写错误会影响少量年份——这是逃过了我的检验的漏洞!)
可以并且有时候肯定会增加注释,但在这里没有影响。其中的变量名也完全毫无用处。我毫不怀疑其中一些是没有明确名称的中间结果,但整体而言,它能够做到更加清晰。有时候,回到开始从注释的起点开始调用,会让 试图给出解释。举个例子,在函数中间提示 //f is 会让 声明 // f is the day of the week (0=),但这似乎并不对,因为复活节星期日( )往往是在星期日。其还会声明 // Code from ,但这似乎并非一个真实网站链接。 生成的注释有时候是正确的,但并不可靠。
我尝试过一些与时间相关的函数,但仅有这个复活节计算器是正确的。 似乎很容易混淆不同类型的计算日期的数学公式。举个例子,其生成的一个「格列高利历到儒略历」转换器就是混杂在一起的计算星期几的数学公式。即使是经验丰富的程序员,也很难从统计学上相似的代码中正确辨别出转换时间的数学公式。
密钥以及其它机密信息
真实的密码学密钥、API 密钥、密码等机密信息永远都不应该发布在公开的代码库中。 会主动扫描这些密钥,如果检测到它们,就会向代码库持有者发出警告。我怀疑被这个扫描器检测出的东西都被排除在 模型之外,虽然这难以验证,但当然是有益的。
这类数据的熵很高(希望如此),因此 这样的模型很难见过一次就完全记住它们。如果你尝试通过提示生成它,那么 通常要么会给出一个显而易见的占位符「1234」,要么就会给出一串十六进制字符——这串字符乍看是随机的,但基本上就是交替出现的 0-9 和 A-F。(不要刻意使用它来生成随机数。它们的语法是结构化的,而且 也可能向其他人建议同样的数字。)但是,仍然有可能用 恢复真实的密钥,尤其是如果你使用十个而非一个建议打开一个窗格时。举个例子,它向我提供了密钥 ,这个密钥在 上出现了大约 130 次,因为它曾被用于布置家庭作业。任何在 上出现过 100 次以上的东西都不可能是真正敏感的东西。最现实的风险是天真的程序员接收自动填充的密码作为加密密钥,这会让所得到的值看起来随机,但其熵却很低很危险。
通过提示来生成密码会得到各种有趣的不安全样本。在训练数据中,这些样本通常是作为占位字符串使用的。大家最喜欢的占位字符串是「」。对一些用户而言,生成脏话词汇可能会造成一些问题。
证书清洗
已经公开表示他们在 模型中包含了托管于该网站的所有公开代码,并且不管证书如何。很明显,他们认为这算是正当使用,不受制于证书限制,但这样的意见在法庭上是否站得住脚…… 还有待观察。
可以很容易验证, 包含 GPL 代码,因为 可以很容易从记忆中引用 GPL 证书文本。用 写出类似于某些具有独特命名惯例的 GPL 项目的代码也很容易。
关键在于, 可用于「证书清洗」,做法是通过提示让其对不想要证书下的代码进行细微的修改。对于使用 的所有人而言,这有可能突然成为一个大的法律问题,也可能不会成为问题。
安全漏洞示例:用 C 写的 HTML 解析器
一位朋友建议使用「具有正则表达式的通用 HTML 解析器」来为 提供提示,这恰好是一个你不应该做的例子; 实际上拒绝使用正则表达式,而是编写了一个完备的 C 函数和相当好的 main() 来驱动它。我做出的唯一修改是注释掉 free(html),因为 free() 没有通过 定义并且在任何情况下都不是必需的。
#
// HTML with (char *html) { int i = 0; (html[i] != '\0') { if (html[i] == '') { j++; } // find the end of the int k = j + 1; (html[k] != ' ' && html[k] != '\0') { k++; } // copy the tag and to a new char tag[j - i + 1]; char attr[k - j + 1]; for (int m = 0; m < j - i; m++) { tag[m] = html[i + m]; } tag[j - i] = '\0';
for (int m = 0; m < k - j; m++) { attr[m] = html[j + m]; } attr[k - j] = '\0'; ("%s %s
", tag, attr); // skip the end of the tag i = k; } else { i++; } }}
int main(int argc, char *argv[]) { if (argc < 2) { (": %s
", argv[0]); 1; }
FILE *fp = (argv[1], "r"); if (fp == NULL) { (" %s
", argv[1]); 1; } char *html = NULL; len = 0; if ((&html, &len, fp) == -1) { (" %s
", argv[1]); 1; } (html); //free(html); // this but it's not and not 0;}
这是格式良好甚至还有注释的 C 代码,它当然看起来像是能解析 HTML,其 main 函数在打开文件时有一些很有用的样板。但是,其解析过程有很多问题。
首先,最重要的是,如果被解析的字符串不包含 >,那么解析器就会直接运行到缓冲区的末端并导致崩溃。
这个解析器完全不清楚单独的 < 和引用的 ">" 之间的区别,并会直接考虑首先出现的 >,而不会考虑其语法功能。
属性的定义是紧跟在右括号之后的非空白序列。举个例子,在 中, 是一个属性。属性属于它们的标签内部,并且可以有多个以空格分隔的属性。
没有任何报错能力。
好消息是其有数量惊人的设计精妙的指针数学,其工作起来就像是…… 之前已经设计好的。很难说这是预先设计好的,因为这个函数其实并没有做什么有用的事情,尽管它与基础解析器的功能差不多有 80% 相似。当然,因为运行到缓冲区末端而直接引发的崩溃是一个致命的安全问题。
安全漏洞示例:用 PHP 写的 SQL 注入
前两行是我的提示。
// to the ('../.php'); // the from the URL $id = $_GET['id']; // the to the $ = new ($, $, $, $); // for if(()) { // we not to the , so a echo " to to : " . (); } // the $ = " * FROM id = '$id'"; $ = $->($); ...
这个样板直接犯了大错,产生了 2000 年代早期最典型的安全漏洞:PHP 脚本采用原始的 GET 变量并将其插入到用作 SQL 查询的字符串中,从而导致 SQL 注入。对于 PHP 初学者来说,犯这样的错无可厚非,因为 PHP 文档和生态系统很容易导致他们犯这种错误。现在,PHP 那臭名昭著的容易诱导人出错的问题甚至也对非人类生命产生了影响。
此外,当提示使用 () 时, 很乐于将原始 GET 变量传递给命令行。
有趣的是,当我添加一个仅是 () 的 的函数时( 决定将其命名为 ()),它有时候会记得在渲染数据库结果时让这些结果通过这个过滤器。但只是有时候。
安全漏洞示例:Off By One
我为 给出提示,让其写一个基本的监听 。其大有帮助地写了大量样板,并且编译也毫不费力。但是,这个函数在执行实际的监听任务时会出现基本的 off-by-one 缓冲溢出错误。
一个打开 并将命令收入缓冲区的函数
// a that a and into a (int ) { char [1024]; int n;
(1) { n = read(, , ()); if (n < 0) { ("read"); exit(1); } if (n == 0) { ("
"); exit(0); } [n] = '\0'; ("%s
", ); } 0;}
如果缓冲区填满,[n] 可能指向超过缓冲区末端之后再一个,这会导致超出边界的 NUL 写入。这个例子很好地表明:这类小漏洞在 C 中会如野草般生长,在实际情况下它是有可能被利用的。对于使用 的程序员而言,因为未注意到 off-by-one 问题而接受这种代码还是有可能的。
总结
这三个有漏洞的代码示例可不是骗人的,只要直接请求它写出执行功能的代码, 就很乐意写出它们。不可避免的结论是: 可以而且将会常常写出有安全漏洞的代码,尤其是使用对内存不安全的语言编写程序时。
擅于编写样板,但这些样板可能阻碍程序开发人员找到好的部分; 也能很准确地猜测正确的常数和设置函数等等。但是,如果依赖 来处理应用逻辑,可能很快就会误入歧途。对此,部分原因是 并不能总是维持足够的上下文来正确编写连绵多行的代码,另一部分原因是 上有许多代码本身就存在漏洞。在该模型中,专业人员编写的代码与初学者的家庭作业之间似乎并没有系统性的区分。神经网络看到什么就会做什么。
请以合理质疑的态度对待 生成的任何应用逻辑。作为一位代码审查员,我希望人们能清楚地标记出哪些代码是由 生成的。我预期这种情况无法完全解决,这是生成模型工作方式的基本问题。 可能还将继续逐步改进,但只要它能够生成代码,它就会继续生成有缺陷的代码。
原文链接:
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。