工作代码用chatgpt ChatGPT编程准确率暴降13%!UIUC&南大新基准让AI代码现原形了
萧箫 发自 凹非寺
量子位 | 公众号
用写代码,已经是不少程序员的常规操作了。
△“至少提速3~5倍”
但你有没有想过,生成的代码,有不少只是“看起来准确”而已?
来自伊利诺伊大学香槟分校和南京大学的一项最新研究表明:
和GPT-4生成代码的准确率,比之前评估的至少要降低13%!

有网友感叹,太多ML论文都在用一些有问题或有局限性的基准来评估模型,来短暂地达到“SOTA”,结果换个测评方法就现出原形了。

还有网友表示,这也说明大模型生成的代码仍然需要人工监督,“AI写代码的黄金时间还没到呢”。

所以,论文提出了一种怎样的新测评方法?
给AI代码考题加大难度
这个新方法名叫,是一个自动化代码评估框架。
具体来说,它会通过改进现有评估数据集的输入多样性和问题描述准确性,来将这些评估基准变得更严格。
一方面是输入多样性。会先根据标准答案,用生成一些种子输入样例(虽然要测的编程能力,但用它生成种子输入似乎也不矛盾doge)
随后,用改进这些种子输入,将它们改得更难、更复杂、更刁钻。
另一方面是问题描述准确性。会将代码需求描述改得更精确,在约束输入条件的同时,补充自然语言问题描述,以提高对模型输出的精确度要求。
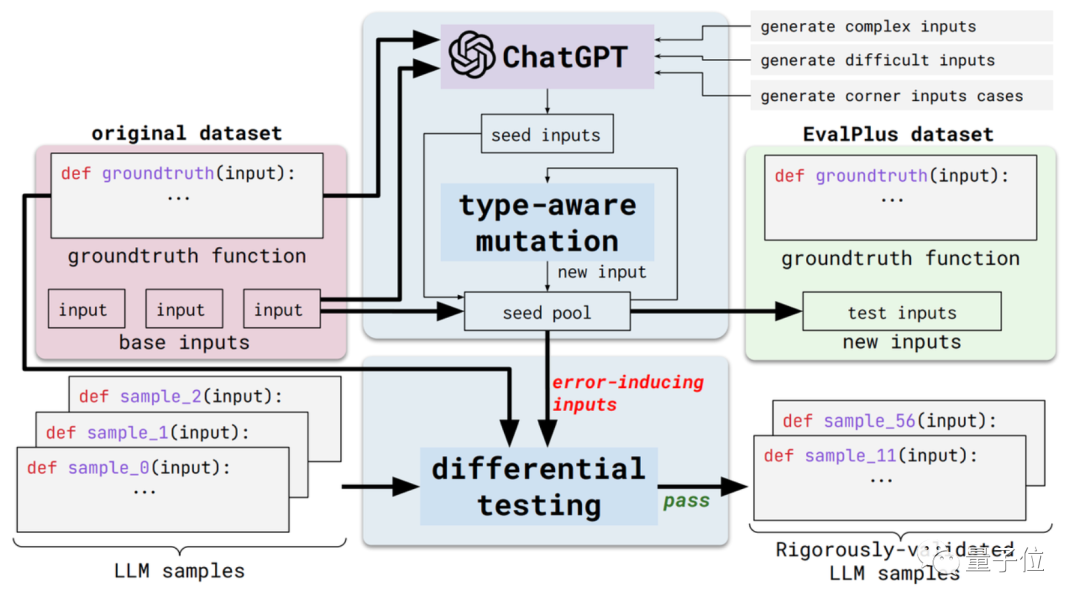
这里,论文选择了数据集作为示范。
是和 AI一起制作的代码数据集,包含164个原创编程题,涉及语言理解、算法、数学和软件面试几种类型的题目。
会通过改进这类数据集的输入类型和功能描述,让编程问题看起来更清晰,同时用于测试的输入更“刁钻”或是更困难。
以其中的一道求并集编程题为例,要求AI写一段代码,找出两个数据列表中的共同元素,并给这些元素排序。
用它来测测写的代码准确度。
首先用几个简单输入进行测试,发现能输出正确答案。但如果换个输入,就找出了版代码的bug:

属实是给AI们加大了考题难度。

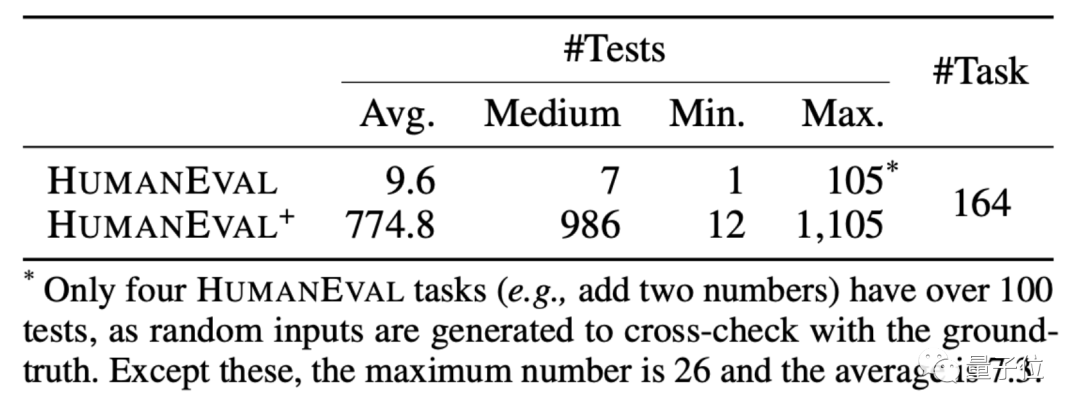
基于这套方法,还做了一个改进版+数据集,增加输入的同时,修正了一些里面答案就有问题的编程题。
那么,在这套“新考题”下工作代码用chatgpt,大语言模型们的准确率实际上要打几折?
LLM代码准确率平均降低15%
作者们测试了当前比较受欢迎的10种代码生成AI。
GPT-4、、、、、、GPT-J、GPT-NEO、、-α。
从表格中来看,经过严格测试后,这群AI的生成准确率都有所下降:
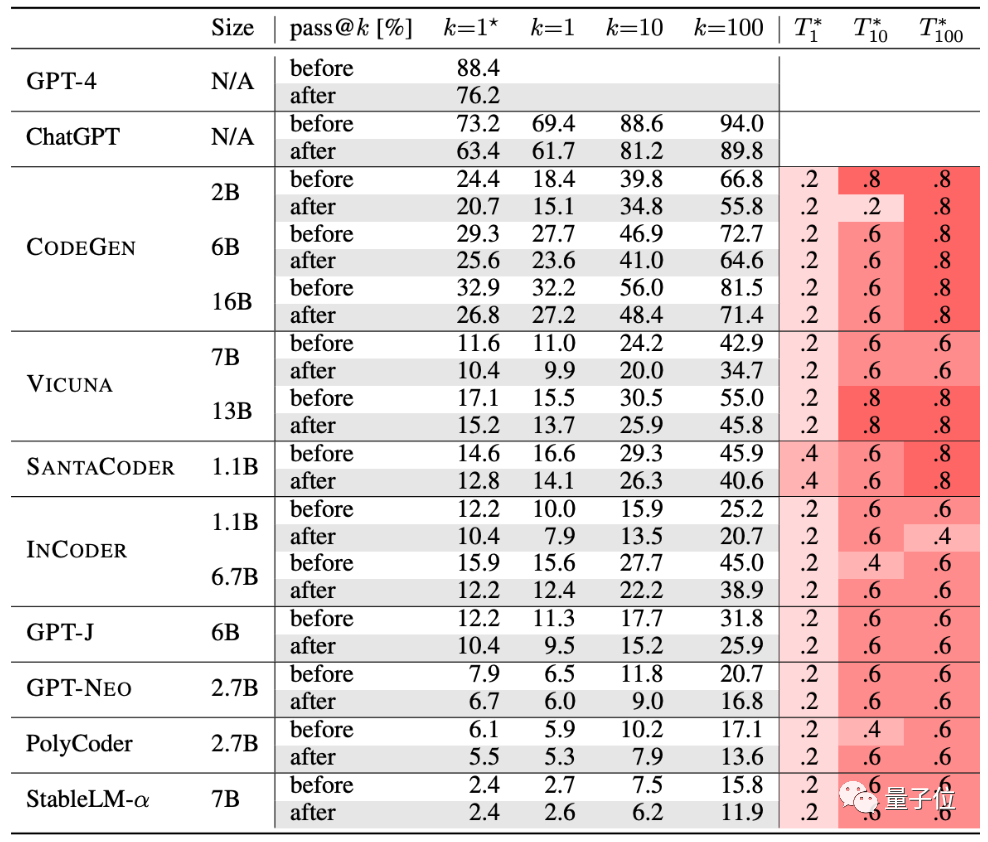
这里会通过一种名叫pass@k的方法评估准确率,其中k是允许大模型给问题生成的程序数量,n是用于测试的输入数量,c是正确的输入数量:
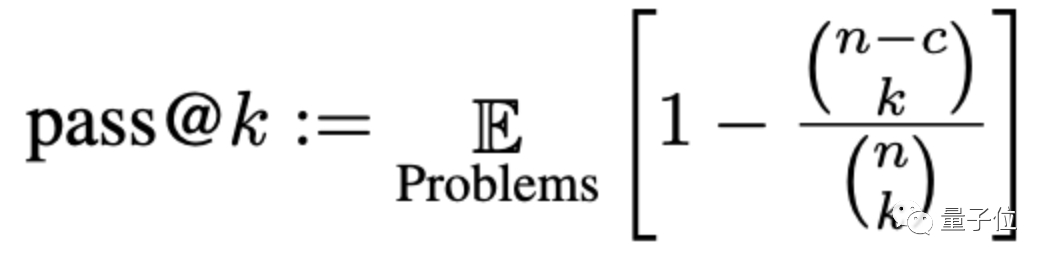
根据新的这套评估标准,大模型们的准确率平均下降了15%,其中比较广泛研究的-16B更是下降了超过18%。
至于和GPT-4生成代码的性能,也下降了至少13%。
不过,也有网友表示工作代码用chatgpt,大模型生成的代码效果没那么好,已经是“众所周知的事实”了,需要研究的是“为什么大模型写的代码不能用”。
作者介绍
共同一作 Liu,伊利诺伊大学香槟分校二年级博士生,研究兴趣是编程系统和深度学习。
共同一作 Xia,伊利诺伊大学香槟分校二年级博士生工作代码用chatgpt,本科毕业于多伦多大学,研究兴趣是机器学习和软件工程的交叉领域。
王宇峣( Wang),南京大学计算机科学大三学生,研究兴趣是计算机系统的准确性、可编程性和性能。
,伊利诺伊大学香槟分校副教授,研究方向是软件工程及其与机器学习、编程语言和形式化方法( )的协同作用。
论文地址:
代码地址:
— 完 —
量子位 · 头条号签约
免责声明:本文系转载,版权归原作者所有;旨在传递信息,不代表本站的观点和立场和对其真实性负责。如需转载,请联系原作者。如果来源标注有误或侵犯了您的合法权益或者其他问题不想在本站发布,来信即删。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。