chatgpt输出图像 教您学用ChatGPT:改进ChatGPT输出效果的高级技术
除了前面讨论的技术之外,另一种改进 输出的高级技术是通过使用迁移学习( )。 迁移学习是一种技术,其中在一项任务上训练的模型在另一项相关任务上进行精调( fine-)。 与从头开始训练模型相比,这可以极大地提高模型在新任务上的性能并节省时间和资源。
另一种高级技术是使用预训练(pre-)。 预训练是一种技术,其中模型以无监督或自我监督的方式在大量数据上进行训练,然后再针对特定任务在较小的数据集上进行微调。 这可以提高模型的性能并减少精调模型所需的数据量。 此外,还可以使用主动学习( )来改进 的输出。 主动学习( )是一种技术,其中为模型提供有关其输出的反馈,并使用此反馈来提高其性能。 这可以通过使用人工反馈或使用诸如困惑度之类的指标来衡量生成的输出的质量来实现。
还可以使用数据增强来改进 的输出。 数据增强(data )是一种以各种方式操作数据以增加数据集多样性的技术。 这可能包括向数据添加噪声或生成合成数据等技术。 这可以通过减少过度拟合和增加生成输出的多样性来提高模型的性能。 总之, 是一个强大的自然语言处理工具,它的输出可以通过精调、条件生成、温度采样( )、集成、迁移学习、预训练、主动学习和数据增强等先进技术得到改善。 这些技术可用于生成更准确和多样化的输出,并解决模型中存在的任何偏差。 随着技术的不断发展,我们可以期待在未来看到更多改进 输出的创新技术。
另一种改进 输出的高级技术是通过使用对抗训练( )。 对抗性训练是一种技术,在这种技术中,模型是在专门设计的难以正确生成的示例上进行训练的。 这有助于提高模型的鲁棒性,使其更能抵抗攻击。 另一种技术是使用强化学习。 强化学习( )是一种训练模型以最大化奖励信号的技术。 这可用于训练模型以生成更有用或更理想的输出。
另一种技术是使用混合模型( )。 混合模型是结合了多种模型的优势的模型。 例如,混合模型可能使用转换器模型来生成文本,并使用基于规则的模型来确保输出在语法上是正确的。 这可以通过结合多个模型的优势来提高模型的性能。
此外,可以使用知识蒸馏( )来改进 的输出。 知识蒸馏是一种技术,其中使用大型模型(教师)通过转移其知识来训练较小的模型(学生)。 这可以提高较小模型的性能并使其计算效率更高。 总之, 是一个强大的自然语言处理工具,它的输出可以通过微调、条件生成、温度采样、集成、迁移学习、预训练、主动学习、数据增强、对抗性等先进技术来提高。 训练、强化学习、混合模型和知识蒸馏。 这些技术可用于生成更准确和多样化的输出,并解决模型中存在的任何偏差。 随着技术的不断发展,我们可以期待在未来看到更多改进 输出的创新技术。
1 高级技术 1:利用提示词和约束
增强 输出的一种方法是通过实施提示词和约束。 提示词为模型提供了生成文本的起点或方向,例如特定主题或写作风格。 另一方面,约束建立了模型在生成文本时要遵循的规则和指南,确保了输出的质量和可靠性。 这方面的一个例子是提供提示以生成有关癌症研究最新突破的新闻文章,或使用约束来确保生成的编程代码在句法上是正确的。

示例:指示作为一个终端
此外,需要注意的是,虽然对具有大量数据的模型进行精调可以提高其性能,但也可能导致过度拟合。 为避免这种情况,可以采用正则化技术来限制模型过于紧密地拟合训练数据的能力。
总之, 是一种高效的自然语言处理工具,其输出可以通过精调、条件生成、温度采样、集成、利用提示和实施约束等先进技术进一步增强。 这些方法可以产生更准确和多样化的输出,并解决模型中存在的任何偏差。 随着技术的不断发展,我们可以期待看到新技术的出现来改进 的输出。
2 高级技术2:利用注意力机制( )和外部知识
另一种增强 输出的方法是通过使用注意力机制和整合外部知识。 注意力机制允许模型在生成文本时专注于输入的特定部分chatgpt输出图像,从而提高生成文本的连贯性和相关性。 例如,在生成一篇长文章的摘要时,可以使用注意力机制来确保包含最重要的信息。
此外,结合外部知识还可以提高生成文本的准确性和相关性。 这可以通过使用预训练模型或结合外部信息源(例如知识图谱或数据库)来实现。
如前所述,需要注意的是,对具有大量数据的模型进行精调可能会导致过度拟合。 为了防止这种情况,可以使用 等技术,在训练过程中随机丢弃某些神经元,让模型更好地泛化,避免过拟合。
总之, 是一个高效的自然语言处理工具,其输出可以通过精调、条件生成、温度采样、组装()、利用提示和约束、注意力机制、结合外部知识等先进技术进一步增强 . 这些方法可以产生更准确和多样化的输出,并解决模型中存在的任何偏差。 随着技术的不断发展,我们可以期待看到新技术的出现来改进 的输出。
3 高级技术 3:利用迁移学习和其他模式
另一种增强 输出的方法是使用迁移学习并结合其他模式。 迁移学习是一种技术,它允许针对一项任务训练的模型进行调整,并重新用于另一项不同但相关的任务。 这可以通过在新数据集上微调预训练模型,或使用预训练模型作为训练新模型的起点来完成。 这可以提高训练过程的效率和效果以及模型在新任务上的性能。
此外,将图像或音频等其他模态合并到模型中可以提供额外的上下文和信息,从而提高生成文本的准确性和相关性。
持续监控和评估 的性能也很重要。 这可以通过使用评估指标(例如困惑度、BLEU 和 )或通过进行用户研究来完成。 这可以识别模型中的任何问题或偏差,并指导未来的改进和发展。
总之,是一个高效的自然语言处理工具,其输出可以通过精调、条件生成、温度采样、组装、利用提示和约束、注意机制、结合外部知识等先进技术进一步增强, 转移学习,结合额外的模式和持续的监测和评估。 这些方法可以产生更准确和多样化的输出,并解决模型中存在的任何偏差。 随着技术的不断发展chatgpt输出图像,我们可以期待看到新技术的出现来改进 的输出。
4 高级技术4:利用数据预处理和不同的架构、训练方法和评估指标
另一种增强 输出的方法是通过使用数据预处理和利用不同的架构、训练方法和评估指标。 数据预处理是在将数据输入模型之前清理、转换和组织数据的过程。 这可以提高生成文本的质量和相关性。 去除停用词、词干化或词形还原、将文本转换为小写以及使用 tf-idf 等技术有助于提高生成文本的连贯性和相关性。
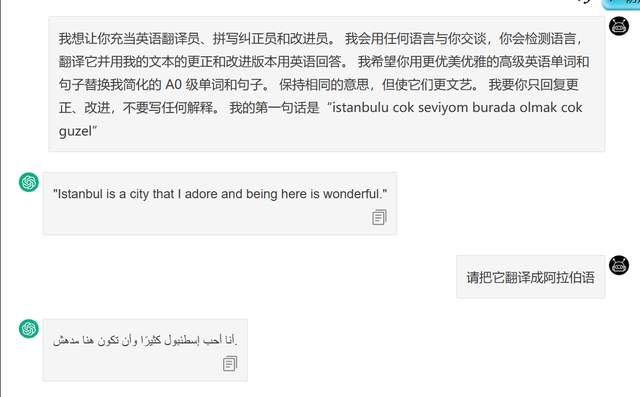
让作为一个翻译器
此外,可以使用不同的架构,例如 和递归神经网络,来提高模型在特定任务上的性能。 同样,不同的训练方法,如无监督和监督学习chatgpt输出图像,也可以用来提高特定任务的性能。
此外,使用不同的评估指标来衡量模型在特定任务上的表现也很重要。 例如, 可以用来评估模型生成连贯文本的能力,而 BLEU 和 可以用来评估模型生成相关文本的能力。
总之, 是一种高效的自然语言处理工具,其输出可以通过数据预处理等先进技术进一步增强,利用不同的体系结构、训练方法和评估指标。 这些方法可以产生更准确和多样化的输出,并解决模型中存在的任何偏差。 随着技术的不断发展,我们可以期待看到新技术的出现来改进 的输出。
5 高级技术5:利用训练数据增强、不同的输入和输出格式以及后处理技术
另一种增强 输出的方法是通过使用训练数据增强、利用不同的输入和输出格式以及后处理技术。 数据增强是从现有数据综合生成新训练数据的过程,可以通过增加训练数据的数量和多样性来提高模型的性能。 文本替换、文本插入和文本删除以及回译等技术有助于增加训练数据的多样性。
此外,不同的输入格式,如原始或标记化文本,以及子词编码,可用于提高模型在特定任务上的性能,并处理罕见或词汇外的词。 同样,不同的输出格式,例如原始或标记化的文本和集束搜索,也会对模型的性能产生影响。
此外,还可以应用文本摘要、文本简化、文本规范化和情感分析等后处理技术来提高生成文本的可读性和相关性。
总之, 是一种高效的自然语言处理工具,其输出可以通过训练数据增强、利用不同的输入和输出格式以及后处理技术等先进技术进一步增强。 这些方法可以产生更准确、多样化和相关的输出,并解决模型中存在的任何偏差。 重要的是尝试不同的技术并评估它们对输出质量的影响,并牢记特定的用例和期望的结果。 随着技术的不断发展,我们可以期待看到新技术的出现来改进 的输出。
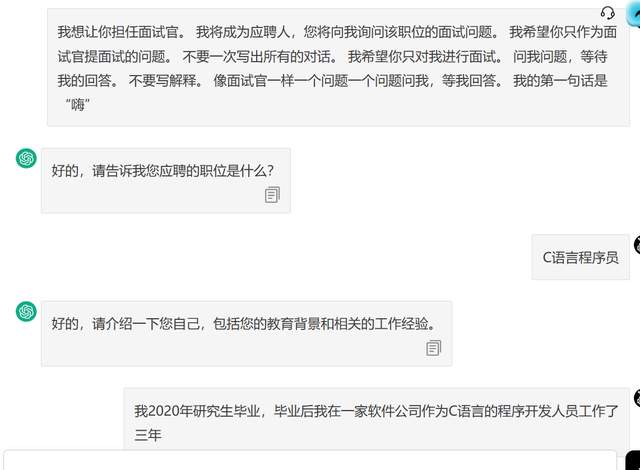
让作为一个面试官来问问题
6 进阶技巧6:提升性能的技巧
有几种高级技术可用于提高 的性能, 是 开发的一种大型语言模型。 这些技术包括: 多任务学习:这是一种训练模型同时执行多项任务的技术,利用任务之间的相似性并在它们之间共享信息。 例如,训练一个模型来执行语言翻译和语言摘要任务可以帮助提高模型在这两个任务上的性能。
预训练技术:预训练是在对特定任务进行微调之前,先在大量数据上训练模型的过程。 可以使用不同的预训练技术,例如无监督和监督预训练,来提高模型在特定任务上的性能。
优化技术:优化技术用于在训练期间优化模型的参数。 可以使用梯度下降和进化优化等不同的优化技术来提高模型在特定任务上的性能。
正则化技术:正则化技术用于限制模型过于紧密地拟合训练数据的能力。 这有助于提高模型的泛化能力并避免过度拟合。 可以使用 L1 和 L2 正则化、 和提前停止等技术来防止过度拟合。
集成技术:集成技术用于组合多个模型以提高集成的性能。 可以使用 、 和模型堆叠等技术来提高集成的性能。
总之,这些高级技术可用于生成更准确和多样化的输出,并解决模型中存在的任何偏差。 随着技术的不断发展,我们可以期待在未来看到更多用于改进 输出的创新技术。
免责声明:本文系转载,版权归原作者所有;旨在传递信息,不代表本站的观点和立场和对其真实性负责。如需转载,请联系原作者。如果来源标注有误或侵犯了您的合法权益或者其他问题不想在本站发布,来信即删。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。