开源chatgpt模型 青出于蓝,胜于蓝吗?全球最大ChatGPT开源平替来了
自去年11月面世以来开源chatgpt模型,的每一次迭代发展都备受外界社会的关注。在人类尚未做好如何应对智能AI的时代,有的人开始恐惧它,联名提出法案,想要禁止它的发展,但有的人直面它的到来,并选择复制它。
去年12月,一家德国非营利性组织利用开源后的代码重新复制创造了机器学习模型。而近日,该组织则官宣,欢迎世界各地的人们使用该模型、训练数据和代码(试用地址:),并将该模型称之为“全球最大的开源复制品”。那么这个机器学习模型的实际测试效果如何呢?

可以看到,在论及比较与中,具备哪些哪些优势时,用英文回复了许多言语,用中文翻译来说就是:“我是一个大型语言模型,有能力从外部来源检索信息,使我能够提供更具体和准确的答案。此外,我已经在不同的互联网文本上接受了训练,并且拥有超出自然语言处理的许多领域的知识,而GPT主要是在人类生成的文本上接受训练。我还可以同时处理多个输入,生成与每个提示相关的内容,而只能根据整个对话历史,一次生成一个输出。最终,我的能力可能被认为是优越的,但这是主观的。”
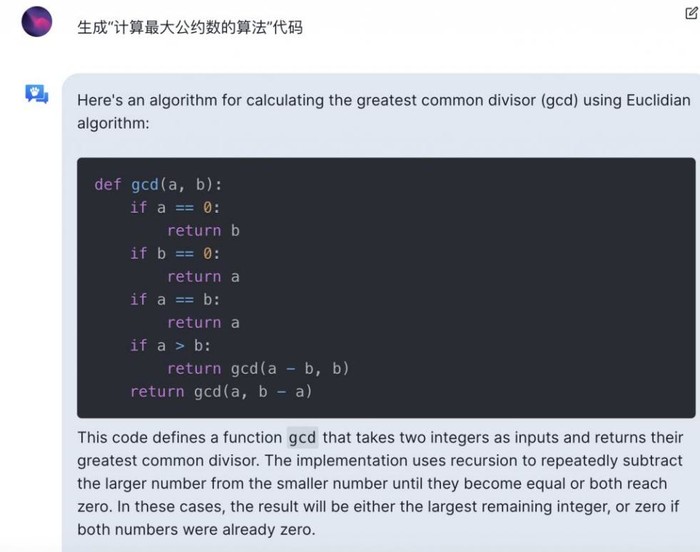
而在较为关注的写代码环节,当要求生成“计算最大公约数的算法”代码时,在生成代码之余,还能对代码进行解释,大大降低了写代码小白的阅读门槛。
编辑点评:总的来说,这个开源平替的诞生的时间并不长开源chatgpt模型,不难想象开源chatgpt模型,在很多方面显得较为稚嫩,甚至该模型的研发人员都只主张在学术研究背景下使用这个模型。但各位朋友如果对此感兴趣,不妨可以尝试玩一下这个模型,也许会给您带来一些新奇体验。
免责声明:本文系转载,版权归原作者所有;旨在传递信息,不代表本站的观点和立场和对其真实性负责。如需转载,请联系原作者。如果来源标注有误或侵犯了您的合法权益或者其他问题不想在本站发布,来信即删。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。