构建chatgpt数据 从大数据的角度看ChatGPT

引起业界的极大关注,作为大数据技术研究人员,更希望从大数据的角度来看待,毕竟在大数据驱动的人工智能时代,此类大模型没有大数据,就如同机器没有电一样。
根据的解释, 是的兄弟模型,两者非常相似,不同之处仅在于训练模型的数据量。目前关于的技术文档比多一些,因此,我们从文档中关于数据部分的描述可以看看。关于、和GPT-3的关系及技术差别见本文最后,这里先将模型的训练数据,包括互联网大数据和对话相关的数据集。下面分别介绍数据集、处理方法、以及爬虫作用。
互联网大数据及处理
模型最主要的数据是互联网大数据,是来 的部分数据,共1万亿个词汇、570G,覆盖了2016-2019年间的互联网文本数据,包括HTML、word、pdf等等各类型。这些数据可通过亚马逊的云计算服务进行访问,据说只需25美元就可以设置一个亚马逊帐户获取这些抓取数据。从页面语言来看构建chatgpt数据,最多的是英文,共有15亿个页面(根据2022年某个月抓取的页面统计)。截至2021年12月,我国网页数量为3350亿个,2021年比2020年增加195亿个页面,每个月新增加16.2亿构建chatgpt数据,因此 收录的中文页面大概不超过总数的10%。除此以外,还有来自英文和基于互联网的两个图书库(具体未知)。
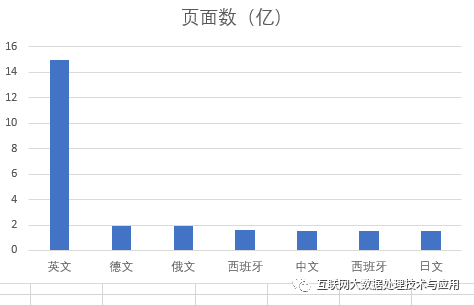
从这里,我们也可以看出,由于训练数据将近50%是英文,在经过多层模型学习后,最终也可能学习到一些所谓“价值观”的高层特征,因此在新的AI时代 文化安全更加富有挑战性。
对数据集进行了两个主要的处理,即 低质量页面过滤、 页面相似性去重,以避免过拟合。这也是采用互联网大数据进行机器学习不可少的步骤。页面质量过滤时,采用的是机器学习方法。选择作为高质量文档类,训练一个文档质量分类器(逻辑回归分类器+的标准切分和作为特征表示),训练好的分类器用于对的文档进行质量过滤。页面去重时,使用和该质量分类器相同的文档特征表示,利用的进行文档相似性计算,大概排除了10%的相似页面,有利于减小相似文档导致的模型过拟合,以及降低模型训练复杂度。
支持对话的相关数据集
GPT-3有很强的上下文表示能力,但缺乏用户交互行为的学习。模型引入了强化学习和监督学习来 理解用户意图,正是由于有了很好的意图理解能力,我们和的对话才能显得自如。相应的支持训练数据主要有:
(1) SFT数据集:由标注人员对用户输入提示行为进行标注,共13K个训练提示,该数据集用于微调GPT-3,采用监督学习方法 fine- (SFT)。
(2) RM数据集:标注者对给定输入的预期输出进行排序,共33K个记录,数据集用于训练奖励模型 (RM)以预测人类想要的输出。
(3) PPO数据集:没有标注,用于RLHF(g from ,从人类反馈中获得的强化学习)微调。

正是由于这些数据集的引入,使得在多轮会话中,能够有效地理解我们的意图,这点倒 是AI一个很大的进步。这里我们也可以看到在AI时代标注之类的劳动密集型工作留给人类来做,按此趋势人类大脑退化不是没有可能的,哈哈~
、GPT-2、关系介绍
是于2022年初发布的语言模型,可以看作是一个经过微调的新版本GPT-3构建chatgpt数据,它的新在于可以尽量减少有害的、不真实的和有偏差的输出。吸取了 的Tay在使用来自 的开放数据进行训练后出现的种族倾向错误。这个是 人工智能安全的视角,在信息化进入智能化后,安全升级为第一要位, 没有安全也就没有AI应用,自动驾驶就是很好的例子。当然目前这个架构,还很 容易受到数据投毒攻击,后续有空我再写一篇人工智能安全视角下的。
这个模型比GPT-3小了100多倍,仅有13亿个参数,比GPT-2还少。与之前各类语言模型不同的是, 是为对话构建的大型语言模型,也可以称之为对话语言模型吧,因此该模型的设计目标之一是能够让模型知道人类的意图。因此,主要技术是通过结合监督学习+从人类反馈中获得的强化学习(RLHF,g from ),提高GPT-3的输出质量。
爬虫的作用
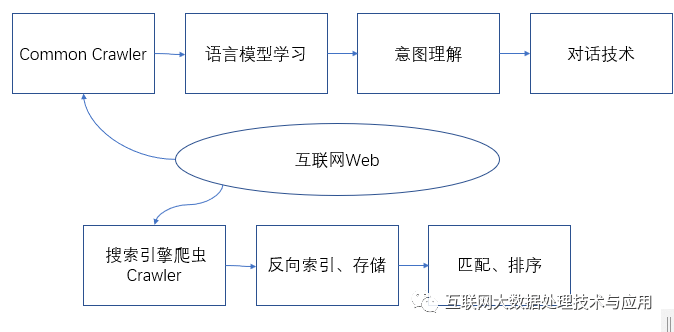
尽管目前还是利用他人爬虫数据集,但是作为一个独立成长的AI系统,将来免不了自己采集,否则难于跟上用户变化。虽然进入了 AIGC时代,但是 UGC仍然长期存在,否组用AIGC去训练AI,那就相当于自己拉的si自己吃了,最终免不了病态。当然并非否定AIGC,它作为一种辅助数据增强的手段还是非常受到大家的欢迎。
从这个角度看它和搜索引擎有一定相似地方,才会有很多人认为它是搜索引擎的增强或者将来要代替搜索引擎了。搜索引擎只是将爬虫抓来的页面提取、解析后进行逆向索引,然后存储关键词和页面的对应关系即可为用户提供匹配服务,而技术手段要更深刻很多了,语义理解、大数据技术、监督学习、强化学习以及意图理解等等。不过搜索引擎公司所拥有的页面数据比所使用的大数据集要大很多,将来自己定制一个对话语言模型是很有基础的,希望不久能出品。
转载请注明:本文来自互联网大数据处理技术与应用公众号。欢迎针对文中提到的一些观点一起讨论,后台留言。
免责声明:本文系转载,版权归原作者所有;旨在传递信息,不代表本站的观点和立场和对其真实性负责。如需转载,请联系原作者。如果来源标注有误或侵犯了您的合法权益或者其他问题不想在本站发布,来信即删。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。