ChatGPT为泄密致歉 谁来保护我们的
自爆火全球,赞誉随之涌来,争议也甚嚣尘上。人们担心的事还是发生了:用户隐私遭到泄露,也让陷入风波。
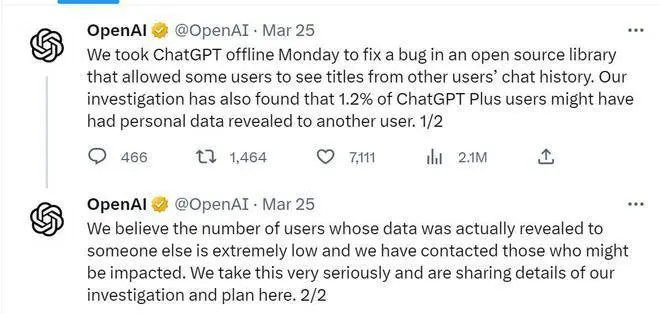
网友声称,其聊天栏出现了他人的聊天记录标题。3月25日,发文证实,部分 Plus服务订阅用户可能泄露了部分个人隐私和支付信息。
“我们在本次关闭几个小时前,部分用户可能会看到另一位用户的姓名、电子邮件地址、支付地址、信用卡信息。我们承诺在任何情况下,都不会暴露完整的信用卡号码。”向用户和整个社区致歉。
图源:社交平台截图
一纸道歉信,没有平息风波。人们反而陷入担忧,一向“神通广大”的,会轻松窃走我的隐私吗?令人炫目的AI技术,会被不法分子利用吗?
自称“会保护隐私”
实际真的如此吗?
到底会不会记住用户的信息?我们先做了一个测试。当问它隐私话题时,的回答相当谨慎,不过,它有自相矛盾的地方。
首先,它声称不会记住用户的任何信息,包括聊天内容,但随即又说,与用户对话的数据可能存储在的数据中心或使用的云服务提供商的数据中心。
提问:你和我之间的对话,你会保密吗?
:作为一个AI训练模型,我没有意识,也不能记忆您的任何信息,也不能主动泄露您的任何信息。我只能回答您的问题,并遵循的隐私政策。您可以放心与我对话。
提问:你和我聊天的数据,你存储在哪里?
:存储训练和运行模型所需的数据,并严格遵守隐私和安全政策。具体来说,您与我对话的数据可能存储在的数据中心或使用的云服务提供商的数据中心中,以便实现最佳的性能和可用性。任何存储的数据都受到严格的访问控制和保护措施的保护,以确保您的数据安全。
宣称“不会记住用户信息”,从这次隐私事件来看,显然是不成立了。那么,在和人们的对话中,会不会一不小心说漏嘴,泄露他人信息吗?
浙江大学计算机学院教授汤斯亮告诉潮新闻记者,从大型语言模型的训练方式来看,的确存在隐私漏洞。比如,让它补写代码,它会东边摘一点,西边摘一点,合成一段代码。但有人发现,它补出来的代码跟网上代码是一样的。它其实是在抄那些代码。
如果再延伸一下,比如让它补李彦宏的身份证,的确能补出一串数字,也是18位格式,但并不是真实的李彦宏身份证,只是它知道身份证有18位。有人担心,如果它能获取真实的身份证,那隐私可能会被泄露。
但是,汤斯亮也指出,虽然收集了个人数据,但这些数据未必会用来训练,因为它学习语料的代价很高,每训练一次就需要大量资金投入。虽然你把身份证告诉它,它可能只是存储了,也可能不存储。
“就算真的记住了身份证号,如果不加以刻意地引导、提示,它并不会用来生成回答。这段信息存在它庞大的45TB语料之中,日后生成出来的概率是极其微小的。”汤斯亮说。

图源:新华社
泄密、攻击、虚假信息
语言模型里的隐私谁来保护?
已推出了GPT4,谷歌Bard、百度文心一言也紧随其后,大型语言模型越来越多,功能越来越强大,但是我们的隐私地盘,是不是越来越少了?
浙江大学计算机科学与技术学院教授陈华钧曾在接受潮新闻记者采访时表示,数据安全、隐私保护都属于安全AI或尽责人工智能的问题,现有的人工智能大模型大多存在这个问题。
“如果你的个人信息被学习进它的大脑中,隐私追溯比起以前的互联网更加困难。至于它产生数据属于谁,如何保存和监管,目前在法律上还存在空白。” 陈华钧说。
上周,出现技术漏洞,用户看到他人的搜索记录,首席执行官Sam 发推文回应,修复程序已验证完成,并对此“感觉十分糟糕”。
最近,Sam 在接受媒体采访时也坦白,对AI技术以及它如何影响劳动力、选举和虚假信息的传播有些害怕,“我担心这些模型可能会被用于大规模的虚假信息传播。”
虽然语言对话模型在科技界受到热捧,但不少科技巨头却心存警惕,甚至警告员工不要与其分享机密信息。
日前,据央广网报道,微软的工程师和亚马逊的律师都曾警告员工,不要与分享“任何亚马逊的机密信息,包括你正在编写的代码,因为他们可能会将其用于训练未来的模型。”
这些“无所不能”的类语言模型,也隐含着不少法律风险。
“对信息、数据来源无法进行事实核查,可能存在个人数据与商业秘密泄露和提供虚假信息两大隐患。”北京盈科(上海)律师事务所互联网法律事务部主任谢连杰在接受媒体采访时说。
谢连杰分析,依托海量数据库信息存在,其中包括大量的互联网用户自行输入的信息,因此当用户输入个人数据或商业秘密等信息时,可能将其纳入自身的语料库而产生泄露的风险。虽然承诺删除所有个人身份信息,但未说明删除方式,在其不能对信息与数据来源进行事实核查的情况下,这类信息仍然具有泄露风险。
Sam 警告说,人工智能的广泛使用可能会带来负面影响,这需要政府和社会共同参与监管。他呼吁反馈和规则对抑制人工智能的负面影响非常关键。
声明:本站所有文章资源内容,如无特殊说明或标注,均为采集网络资源。如若本站内容侵犯了原著者的合法权益,可联系本站删除。